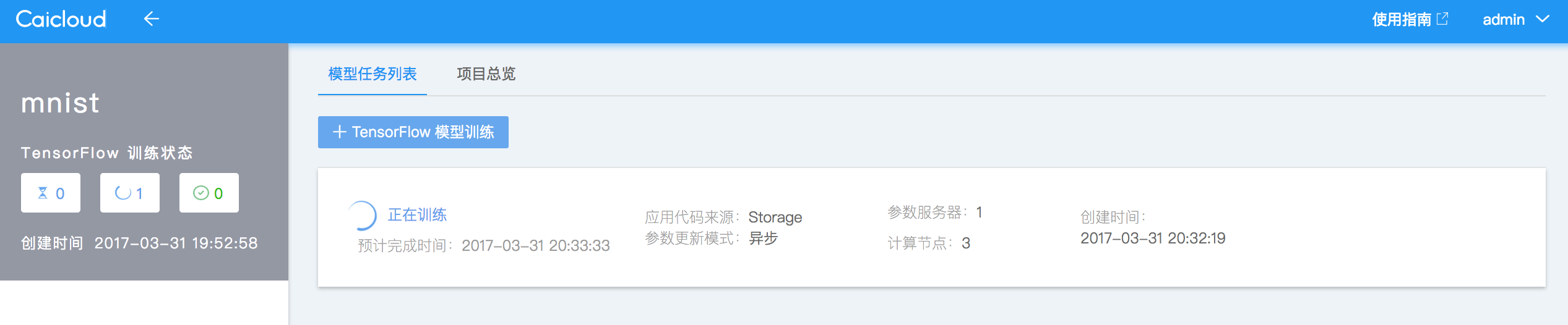
新建分布式 TensorFlow 模型训练
项目详情页面的模型任务列表页签中会显示新建 TensorFlow 模型训练任务的按钮。如下图所示:
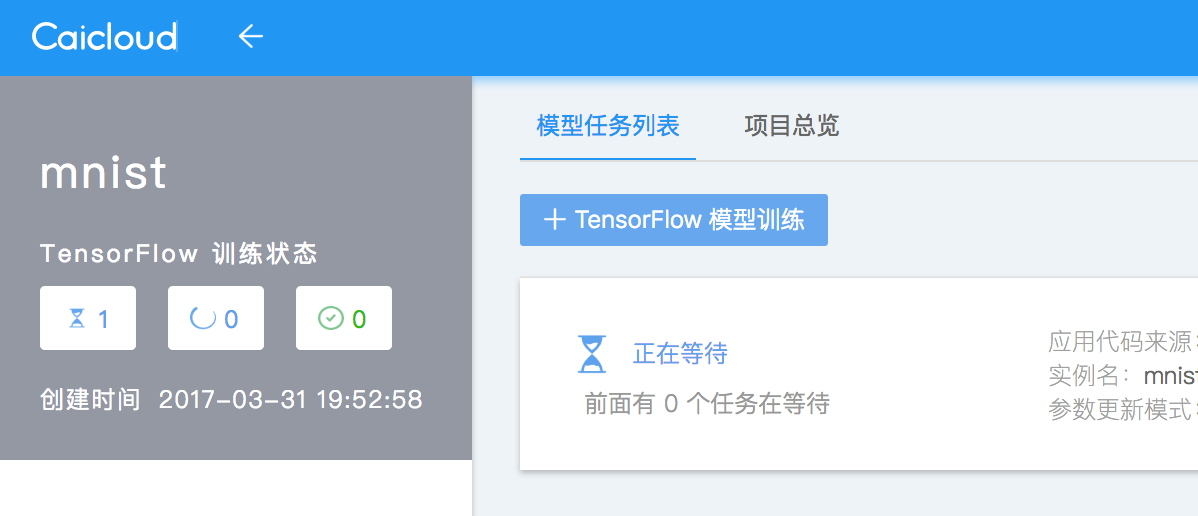
自定义分布式 TensorFlow 模型训练代码可以参考代码开发指南来开发。然后将开发的分布式 TensorFlow 模型训练代码上传到 TaaS 平台的数据存储中。
下面我们通过 caicloud/tensorflow-tutorial 提供的 MNIST 样例代码 来演示如何提交一个自定义的分布式 TensorFlow 模型训练。首先我们将 MNIST 样例代码文件 mnist_export.py 文件上传到 TaaS 平台数据存储的目录 mnist-demo 中,如下图所示,

分布式 TensorFlow 模型训练参数
新建分布式 TensorFlow 模型训练任务时,需要提供下面参数:
- 资源配置:每个 TensorFlow 计算节点所需最大资源(CPU和内存)。
- 应用代码:TensorFlow 模型训练的详细代码信息。
- 运行参数:执行一次模型训练任务需要的运行参数。
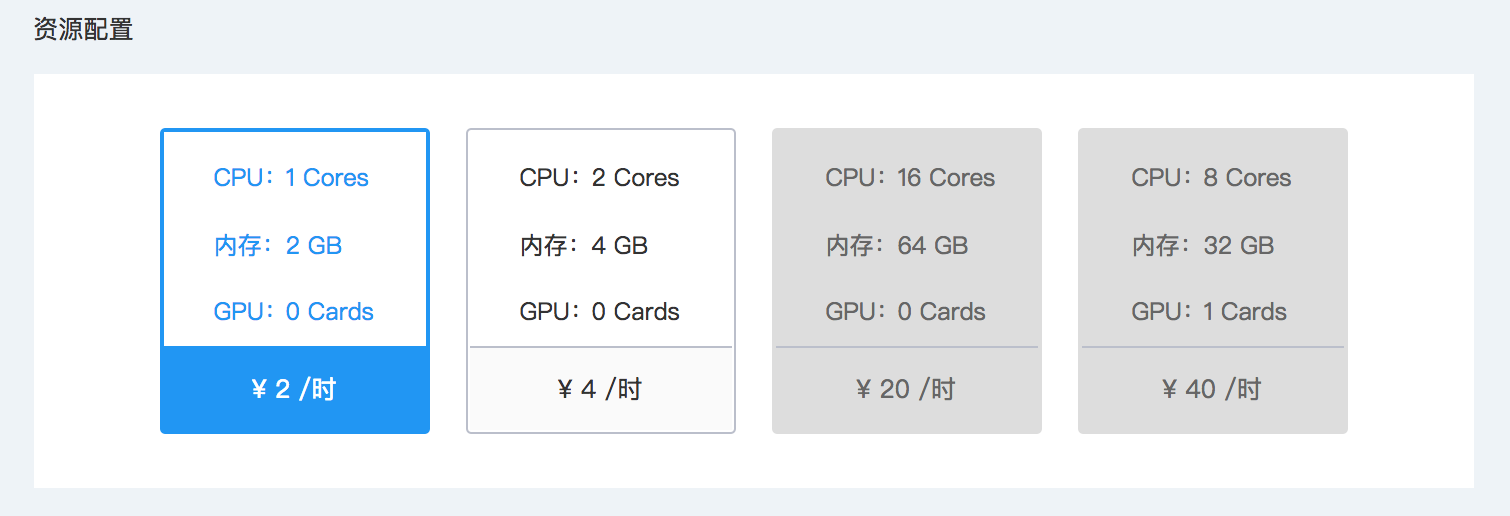
资源配置
资源配置中选择每个计算节点(worker)所需的最大资源(CPU和内存)。
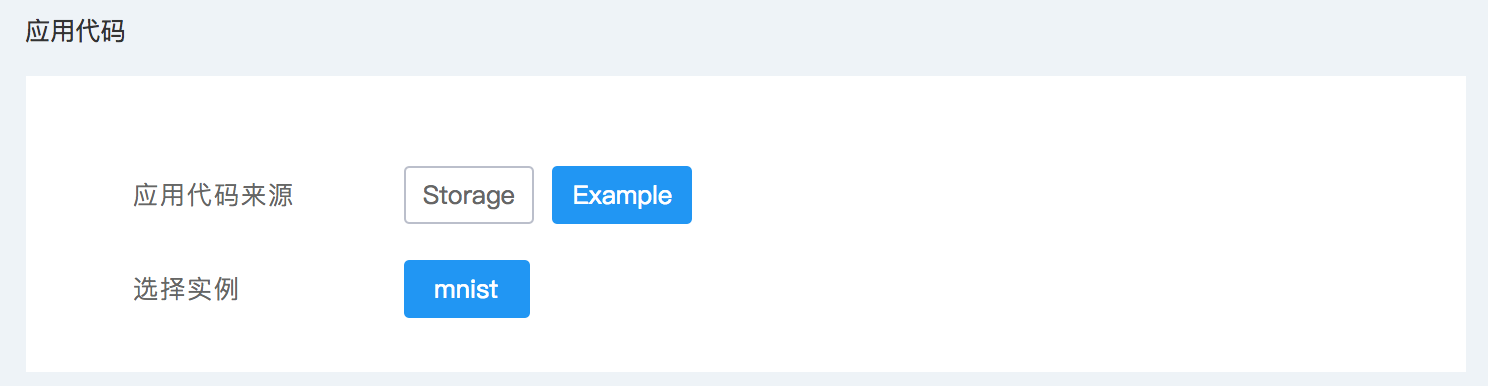
应用代码
在应用代码中提供模型训练任务要执行的任务代码。通过“应用代码来源“选择要是内置的模型任务任务还是自己的模型训练代码。
内置模型训练任务
为了方便快速体验 TaaS 平台的模型训练功能特性,TaaS 内置了简单的手写识别体 MNIST 样例任务。
自定义模型训练代码
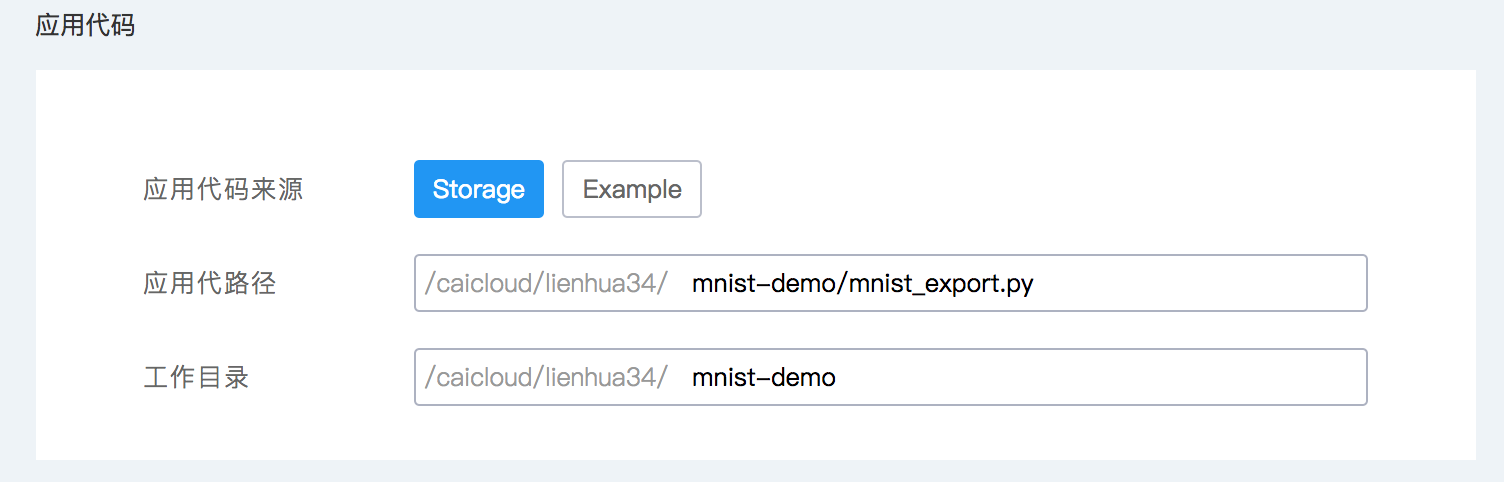
“应用代码来源”选择 Storage 来提供自己的模型训练代码文件。
- 应用代码路径:模型训练任务的入口 python 文件。
- 工作目录:设置模型训练进程的当前工作目录,代码中的相对路径将基于该目录。可以不填写,默认将会是入口 python 文件所在的目录。
运行参数
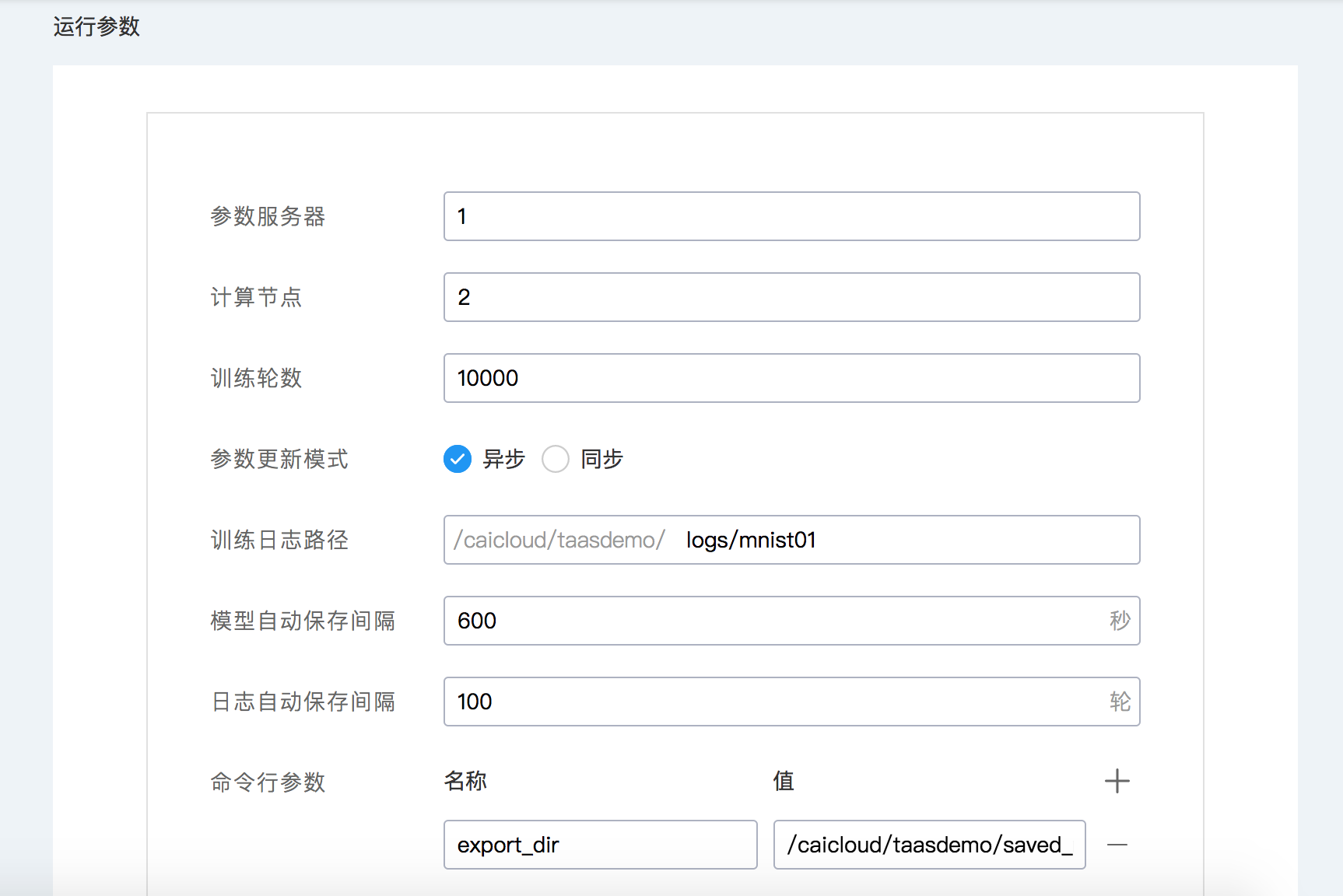
在运行参数中填写一次模型训练相关的参数,例如训练的最大轮数、是否使用参数同步更新模式(需要在业务代码中支持才行,否则会训练失败,参考模型参数同步更新)等,另外还可以设置模型自动保存时间间隔、日志自动保存轮数间隔和命令行参数等信息。
- 参数服务器个数:参数服务器用于分布式 TensorFlow 模型训练时存储模型的参数。
- 计算节点个数:计算节点负责在每轮开始训练之前从参数服务器获取模型参数,执行训练,然后更新参数服务器上的模型参数。
- 训练轮数:模型训练的最大轮数。
- 参数更新模式:异步或者同步。
- 日志路径:模型训练过程中自动保存的模型 checkpoint 文件和 Summary 数据的目录。
- 模型自动保存间隔:自动保存模型 checkpoint 的时间间隔,单位秒。
- 日志自动保存间隔:自动保存模型训练 Summary 数据的轮数间隔。
另外,还提供了命令行参数的设置。在 mnist_export.py 文件定义了一个 export_dir 用于指定模型导出路径。
单机模型训练任务
将参数服务器个数设置为 0,计算节点为 1,表示启动一个单机模型训练任务。

提交
填写完所有信息之后,点击确定按钮提交模型训练任务。